Üsna sageli tahetakse uurida inimeste, olendite, esemete või nähtuste kogumit (hulka) kui tervikut mingi omaduse või tunnuse seisukohalt. Nii näiteks võidakse tunda huvi, milline on Eestis elavate 17-aastaste noormeeste keskmine pikkus, kummas paralleelklassis läks matemaatika eksamitöö paremini, kuidas jaotuvad ettevõtted Eestis tööliste arvu järgi, milline on lilla sireli õite jaotus õielehtede arvu järgi. Kuidas koguda vastavaid andmeid, neid esitada, uurida ja järeldusi teha – sellega tegeleb matemaatika osa, mille nimetuseks on matemaatiline statistika. Matemaatiline statistika tugineb seejuures suuresti tõenäosusteooriale.
Uuritavat kogumit, mille kui terviku kohta tahetakse järeldusi teha, nimetatakse statistiliseks kogumiks. Seda ei uurita tavaliselt kõikvõimalikest aspektidest vaid mingi (või mõne) tunnuse (omaduse) seisukohalt. Tunnuseks võivad olla näiteks inimeste pikkus, õpilaste hinne matemaatika eksamil, töötajate palk, rahvus, terade arv viljapeas.
Tunnused liigituvad arvulisteks ja mittearvulisteks. Arvuline tunnus ehk arvtunnus on tunnus, mille väärtusteks on arvud. Näiteks inimese pikkus, terade arv viljapeas, palga suurus. Mittearvuline tunnus on tunnus, mille väärtusteks ei ole arvud. Näiteks rahvus, silmade värv.
Arvulised tunnused jaotatakse omakorda kaheks: pidevateks ja diskreetseteks. Pidevaks tunnuseks nimetatakse tunnust, mis võib saada kõiki reaalarvulisi väärtusi mingist piirkonnast. Sellised tunnused on näiteks kehakaal, temperatuur. Diskreetseks tunnuseks nimetatakse tunnust, mis võib saada vaid üksikuid eraldiseisvaid (tavaliselt täisarvulisi) väärtusi. Sellised tunnused on näiteks seemnete arv viljapeas, tähtede arv sõnas, lehekülgede arv raamatus.
Diskreetse ja pideva tunnuse eristamine on mõneti tinglik. Pidevat tunnust (näiteks vanus) käsitletakse sageli diskreetsena (üldiselt mõõdetakse vanust täisaastates).
Tunnust, mille järgi vaadeldavat kogumit uuritakse, tähistatakse suurtähega, tavaliselt X, Y, Z. Tunnuse suvalist väärtust (ka mittearvulise tunnuse korral) aga vastava väiketähega x, y, z. Konkreetse väärtuse märkimiseks lisatakse väiketähele indeks: x1, x2, …
Uuritava kogumi objektide mõõtmisel saadakse vaadeldava tunnuse väärtuste rida, nn statistiline rida:
a1, a2, a3, …, aN.
Igat arvu (väärtust) selles reas nimetatakse statistilise rea liikmeks. Tunnuse väärtuste arvu N nimetatakse kogumi mahuks või statistilise rea mahuks. Et statistiline rida ei ole ülevaatlik (andmed esinevad reas mõõtmise järjekorras), siis on otstarbekas seda korrastada. Selleks kirjutatakse rea liikmed kas kasvavas või kahanevas järjekorras, kusjuures võrdsed liikmed kirjutatakse järjest. Tulemusena saadakse nn variatsioonrida.
Näide 1.
Ühe klassi kontrolltöö hinnete variatsioonrida oli järgmine:
2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5.
Siit on küll kerge leida hinnete vähimat väärtust (amin = 2) ja suurimat väärtust (amax = 5), kuid vähegi mahukama kogumi korral on andmete selline esitus ikka kohmakas, kasvõi pikkuse pärast.
Variatsioonreast parem on näite 1 andmete esitamine sagedustabelina, kus igale hindele (x) vastab tema esinemise arv ( f ):
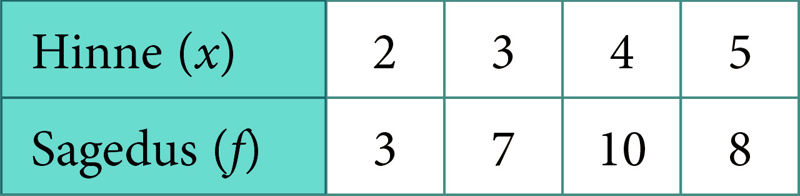
Tabelist saab kiirema ülevaate hinnete jaotusest ning lihtne on leida, et kõige sagedamini esineb hinne 4. Ka kogumi mahu N saab kergesti: N = 3 + 7 + 10 + 8 = 28.
Sagedustabel esitatakse kas
horisontaalsena
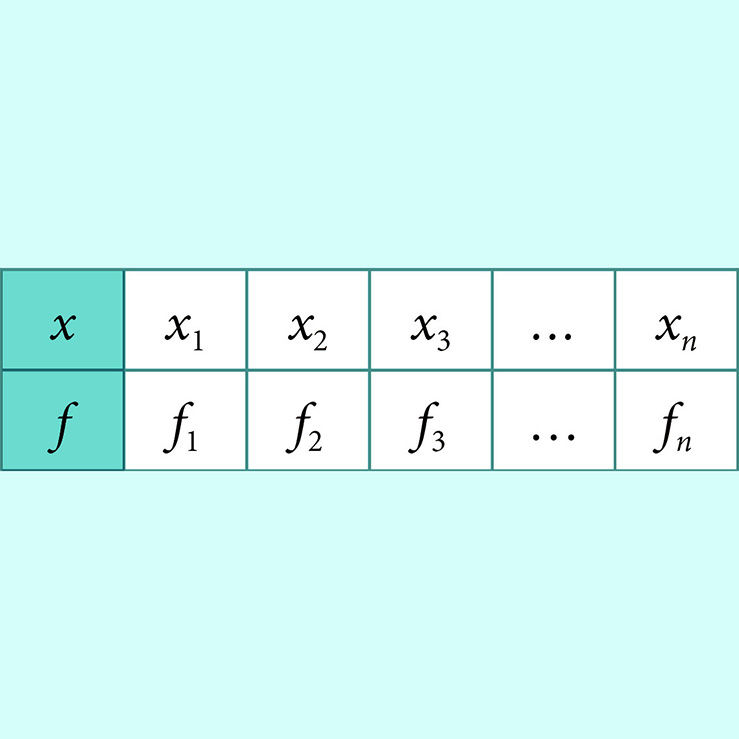 | ||||||
või vertikaalsena.
 | ||||||
Kogumi maht
N = f1 + f2 + f3 + … + fn.
Parema üldpildi saamiseks andmete muutumisest kujutatakse need geomeetriliselt sirglõikdiagrammina, mida nimetatakse sagedushulknurgaks (ka sagedusmurdjooneks). Joonisel 1.17 on esitatud näite 1 andmetele vastav sagedushulknurk.
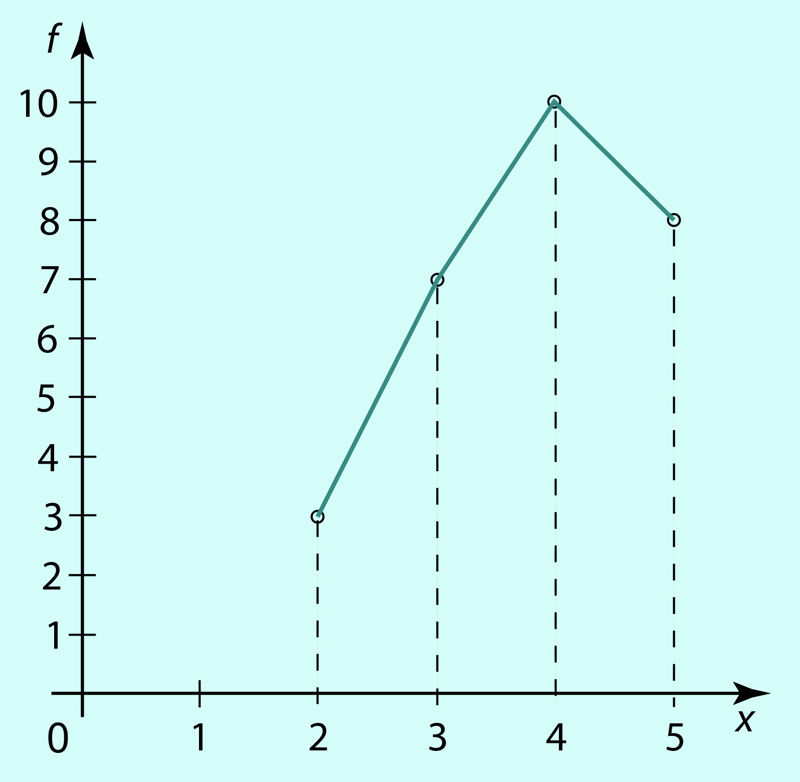
Kahe kogumi võrdlemiseks mingi tunnuse järgi võrreldakse vastavaid sagedustabeleid või sagedushulknurki. Seda on aga tülikas teha ja see ei anna ka kiirelt õigeid järeldusi, kui kogumite mahud on erinevad.
Näide 2.
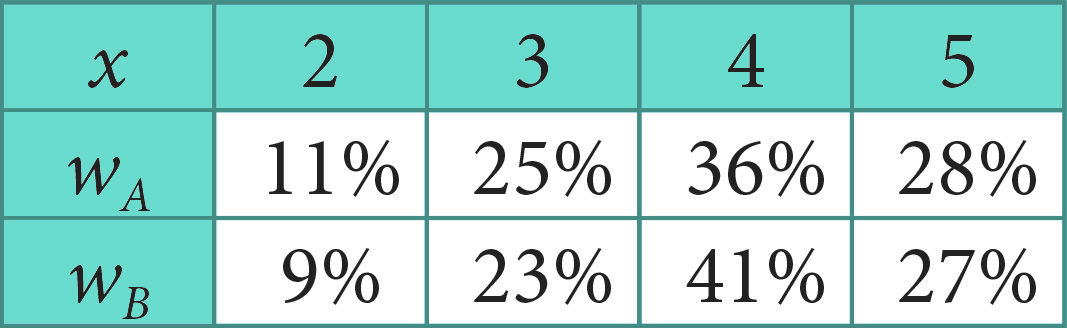
Järgnevas tabelis on esitatud sama kontrolltöö tulemused nii klassis A (näite 1 andmed) kui ka klassis B. Kummas klassis tehti töö paremini?
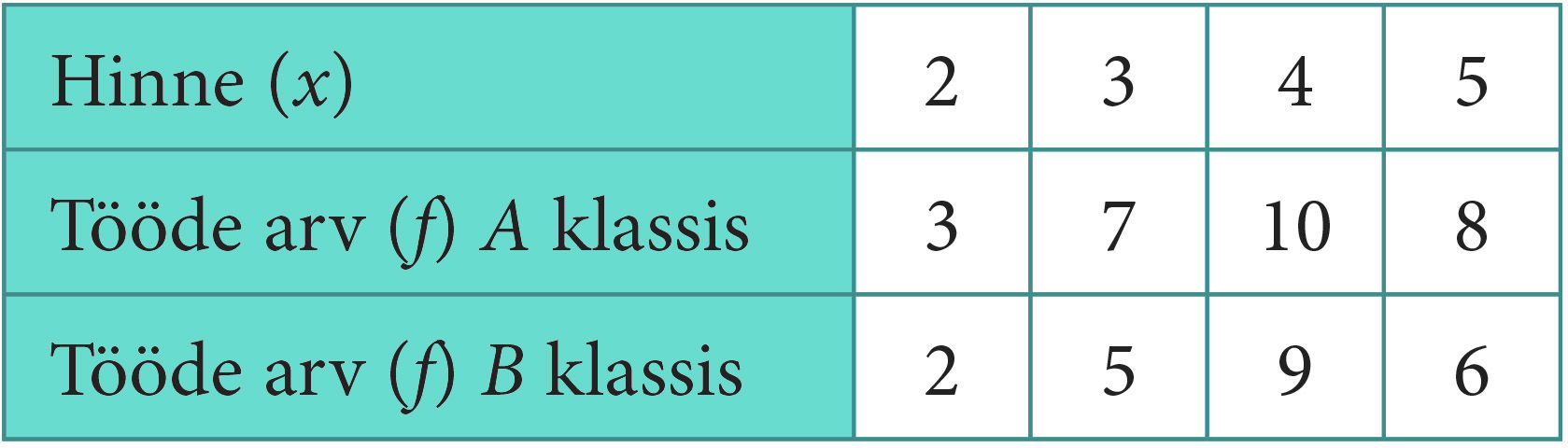
Andmeid on raske võrrelda, sest vastavad diagrammid (joon. 1.18) on küll sarnase kujuga, kuid ühel juhul oli kontrolltöö tegijaid 28, teisel juhul aga 22. Seega ei ole selge, milline on ühe või teise hinde osakaal vastava klassi kõigi hinnete seas.
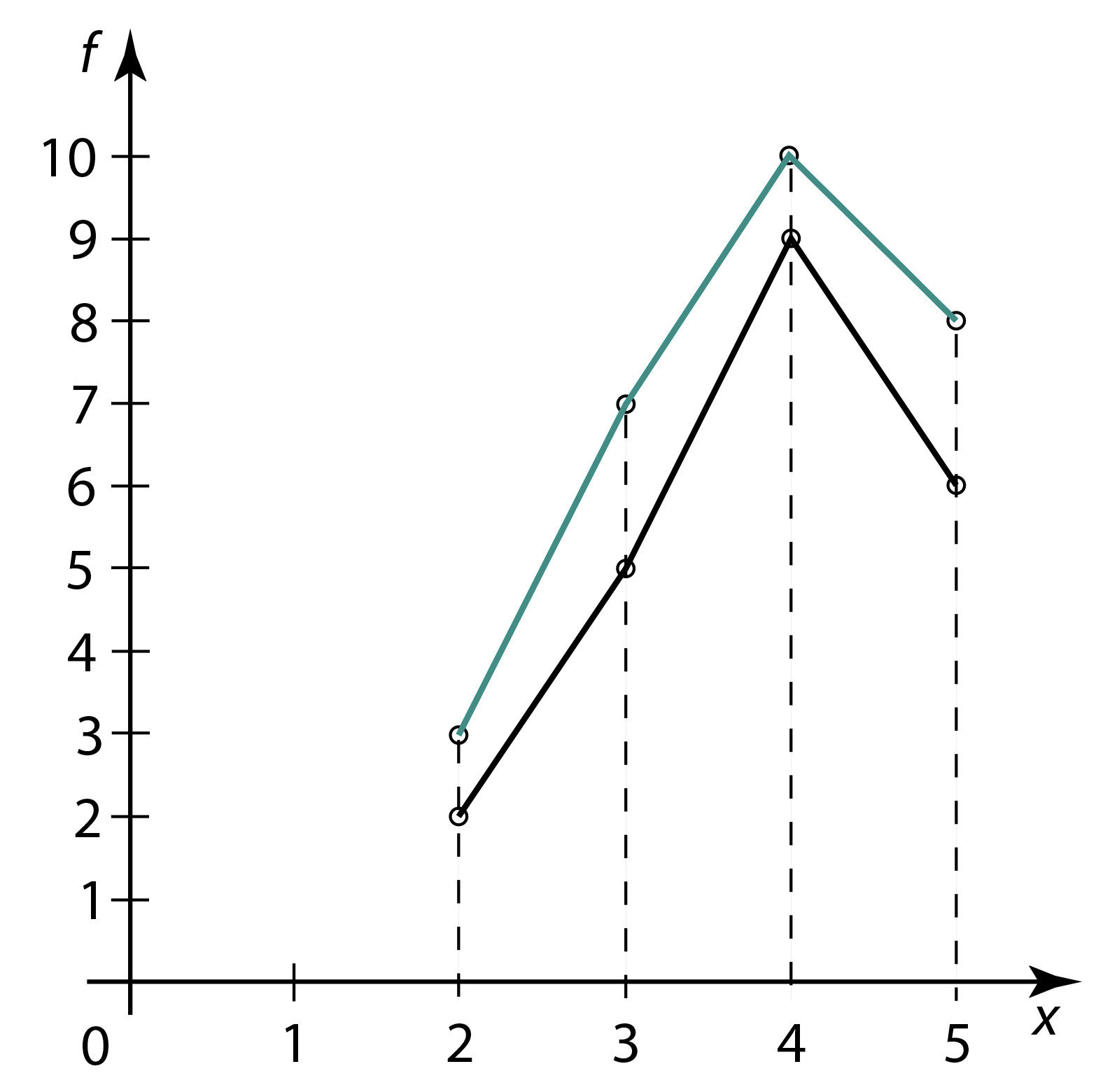 Joon. 1.18 | ||||||
Erineva mahuga kogumite võrdlemiseks, nagu näite 2 korral, on otstarbekas kasutada sageduste asemel suhtelisi sagedusi. Suhteline sagedus antakse kas arvuna
Tabelit, kus tunnuse väärtustele on seatud vastavusse nende esinemise suhteline sagedus, nimetatakse jaotustabeliks.
Üldtähistuses on jaotustabel järgmine:

Seejuures on w1 + w2 + w3 + … + wn = 1, kui
Jaotustabelile vastavat sirglõikdiagrammi nimetatakse jaotushulknurgaks (ka jaotuspolügooniks).
Näide 3.
Tabelis on näites 2 esitatud hinnete sagedustabelite põhjal koostatud jaotustabelid. Joonisel 1.19 on vastavad jaotushulknurgad.
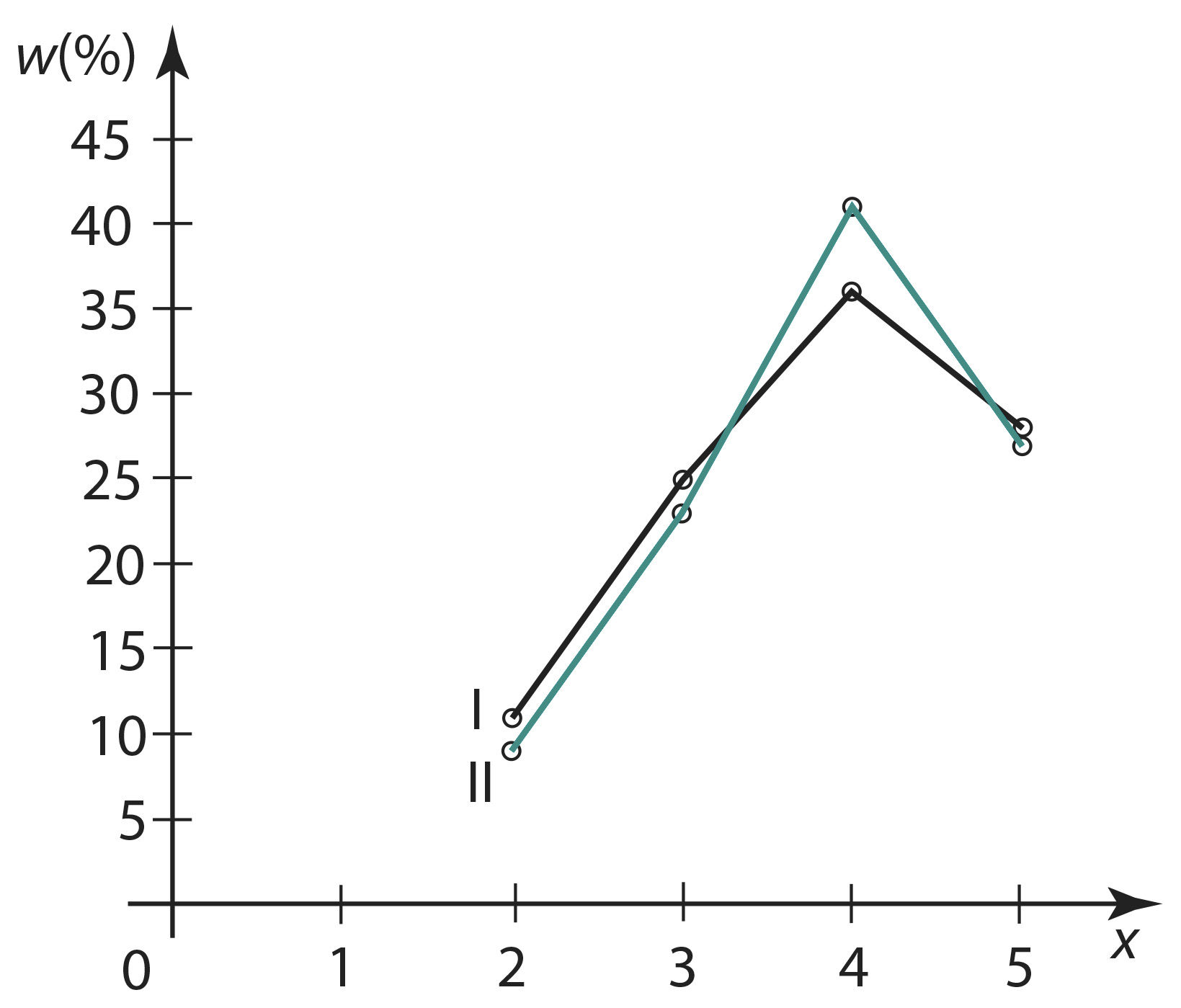 Joon. 1.19 | ||||||
Nii tabeli kui ka joonise põhjal selgub, et B klassis on kontrolltöö tehtud mõnevõrra paremini: hinnete „2” ja „3” osakaal on vähenenud, veidi on vähenenud küll ka hinde „5” osakaal, kuid hinde „4” osakaal on oluliselt tõusnud. Öeldut kinnitab hinnete „4” ja „5” suhteliste sageduste summaarne võrdlemine: 64% ja 68%.
Kui kogumi tunnus on pidev või diskreetse tunnuse erinevaid väärtusi on väga palju, ei esitata andmete tabelis tunnuse üksikuid väärtusi, vaid väärtuste vahemikud ehk klassid. Nii saadakse rühmitatud sagedus- või jaotustabelid. Vahemike otspunkte nimetatakse siis klassipiirideks. Selline tabel on esitatud ülesandes 155.
Kui vahemike otspunktid on tabelis esitatud nii, et kõigi vahemike esimesed otspunktid on võrdsed eelmise vahemiku (nn madalama vahemiku) teise otspunktiga, loetakse kahe vahemiku piiril olev arv madalamasse vahemikku kuuluvaks. Niisugune tabel on esitatud näites 4.
Tunnuse väärtuse vahemike arv sõltub uuritavast nähtusest ja uurimiseesmärgist. Üks „jäme” reegel on järgmine: kui kogumi maht N pole väga suur, on sobiv vahemike arv umbes
Näide 4.
Ühe klassi õpilaste pikkuste variatsioonrida on järgmine: 156, 158, 159, 160, 160, 162, 163, 163, 163, 165, 165, 165, 166, 166, 167, 167, 167, 167, 168, 168, 168, 169, 170, 171, 171, 172, 173, 173, 173, 174, 174, 176, 184. Koostame vastava sagedustabeli ja jaotustabeli, kus tunnuse väärtused on esitatud vahemikes.
Et N = 33 ja
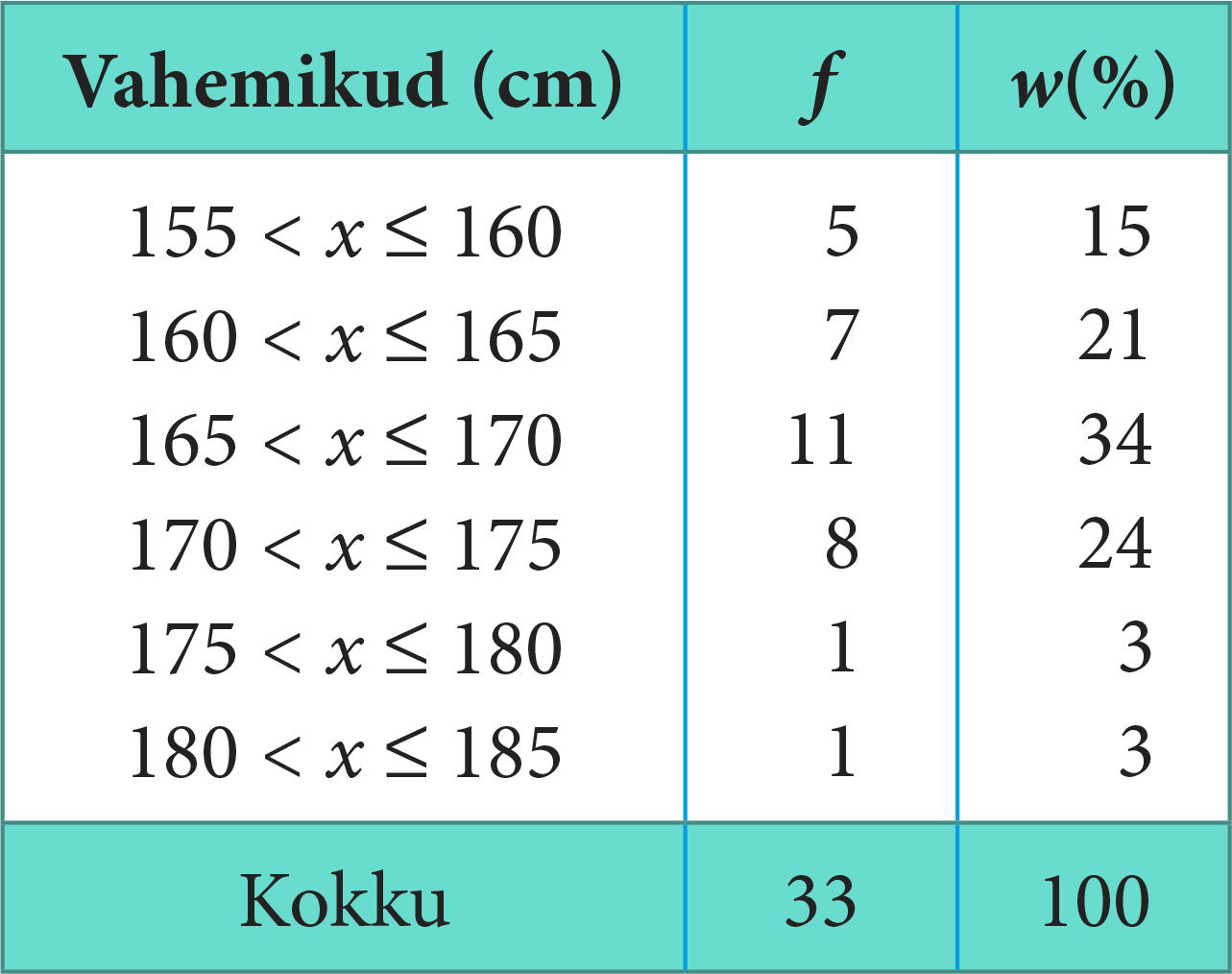 | ||||||
Vahemikke võib märkida võrratusena nagu näites 4, kujul 155…160, 160…165 jne või kujul 155–160, 160–165 jne.
Kui sagedus- või jaotustabelis on tunnuse väärtused esitatud vahemikena, kujutatakse neid andmeid geomeetriliselt tulpdiagrammina, mida nimetatakse histogrammiks. Näite 4 jaotustabelile vastav histogramm on joonisel 1.20.
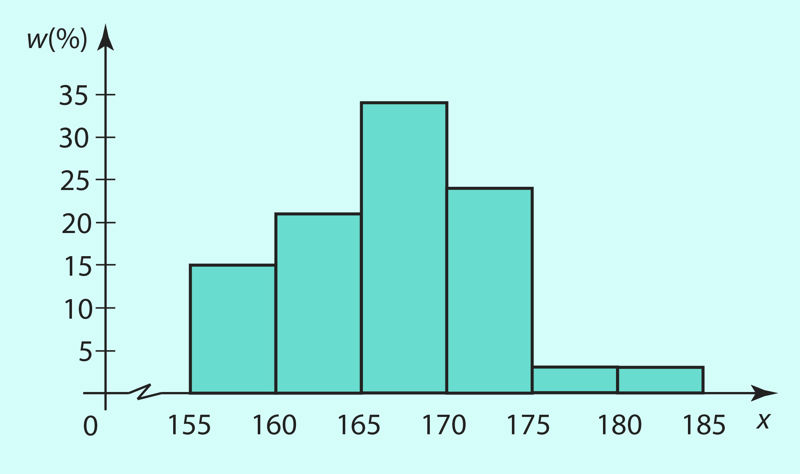
Otsmised vahemikud võivad olla ka lahtised, s.t esimese vahemiku alumine piir ja viimase vahemiku ülemine piir jäävad fikseerimata. Näite 4 puhul oleks siis esimene vahemik x ≤ 160 ja viimane vahemik 180 < x. Histogrammil jääb sel juhul esimene ja viimane vertikaallõik joonestamata.
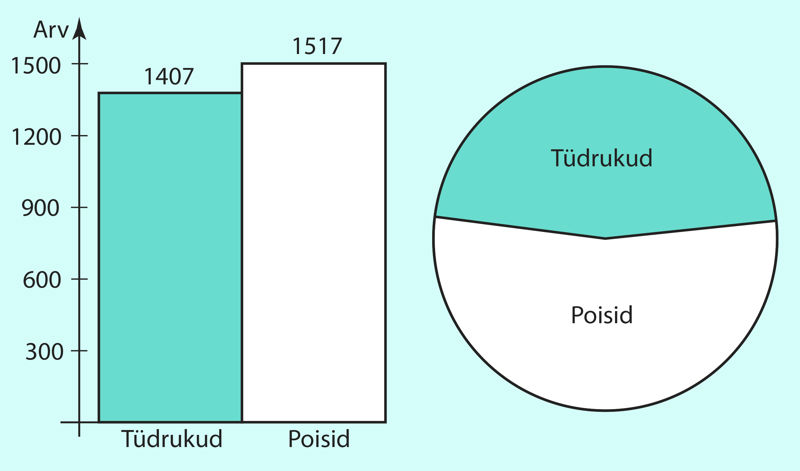
Histogrammiga esitatakse tunnuse jaotus ka siis, kui tunnus on mittearvuline. Samuti sobib sel juhul hästi ka sektordiagramm. Näiteks joonisel 1.21 on esitatud 1990. a Tartus sündinud laste sagedushistogramm ja sektordiagramm soo järgi.
Ülesanded A
Ülesanne 149. Arvuline, mittearvuline, pidev ja diskreetne tunnus
- kinganumber
- haridus
- vanus
- kasv
- sünniaasta
- töötasu
- nimi
- sugu
- töökoht
Ülesanne 150. Kingade müümine
- Arvuline
- Mittearvuline
- Pidev
- Diskreetne
Täitke vastav sagedustabel ja joonestage diagramm.
Kinga number (x) | 38 | 39 | 40 | 41 | 42 | 43 | 44 |
Sagedus (f) |
Milliseid kingi müüdi poes selle tunni jooksul kõige enam, milliseid kõige vähem?
Vastus. Kõige enam müüdi number kingi ja kõige vähem müüdi numbritega ja kingi.
Ülesanne 151. Kinganumbrid
Vastus. Neidude kõige sagedamini esinev kinganumber on ja noormeestel . Meie klassi neidude kinganumber muutub st ni ja noormeestel st ni.
Ülesanne 152. Matemaatika kontrolltöö hinded
Ülesanne 153. Õpilaste pikkused 5 klassina
Vahemikud (cm) | f | w(%) |
< x ≤ | ||
< x ≤ | ||
< x ≤ | ||
< x ≤ | ||
< x ≤ | ||
Kokku |
Ülesanne 154. Pikkuste jaotustabelid
Vastus. Neidude pikkus muutub st ni ja noormeestel st ni. Kõige sagedamini esinevate pikkuste vahemik on neidudel ja noormeestel .
Ülesanne 155. Eesti rahvastik 2011. aastal
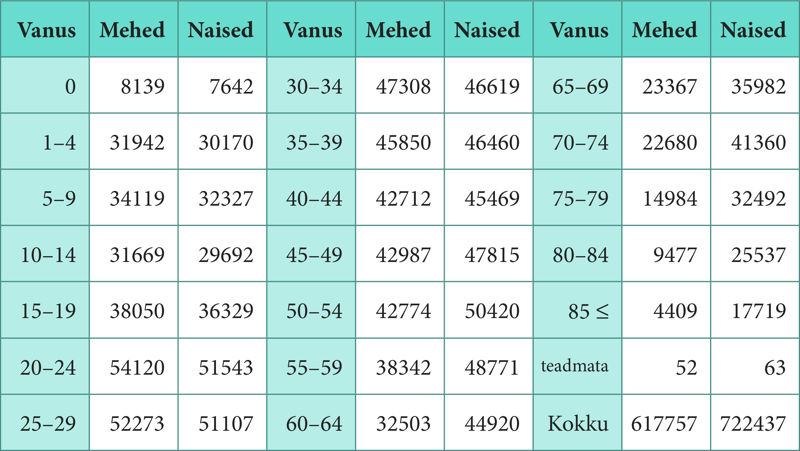
- Kui suur oli tõenäosus, et tänaval kohatav alla ühe aastane laps on poiss?
Vastus. Tõenäosus, et tänaval kohatav alla ühe aastane laps on poiss, oli . - Koostage jaotustabelid ja histogrammid (sobiv on seda teha arvuti abil) vanuse järgi naiste ning meeste kohta eraldi.
- Millises vanuses hakkas naiste arv ületama meeste arvu?
Vastus. Naiste arv hakkas ületama meeste arvu vanuses . - Mitu protsenti moodustasid alla aastased lapsed kogu rahvastikust?
Vastus. Alla aastased lapsed moodustasid kogu rahvastikust %. - Mitu protsenti rahvastikust oli 10 kuni 14 aasta vanuseid lapsi kokku, kuidas need jaotusid soo järgi?
Vastus. 10 kuni 14 aasta vanuseid lapsi kokku oli kogu rahvastikust %. Neist % olid poisid ja % tüdrukud. - Mitu protsenti oli pensionäre (alates vanusest 65) meeste ja naiste seas eraldi, kokku kogu rahvastikust?
Vastus. Pensionäre oli % meestest ja % naistest ning kogu rahvastikust oli nende osakaal %. - Mitu naist tuli ühe mehe kohta vanuses 20–29 aastat ja vanuses 30–39?
Vastus. Vanuses 20–29 oli ühe mehe kohta naist ja vanuses 30–39 oli ühe mehe kohta naist.
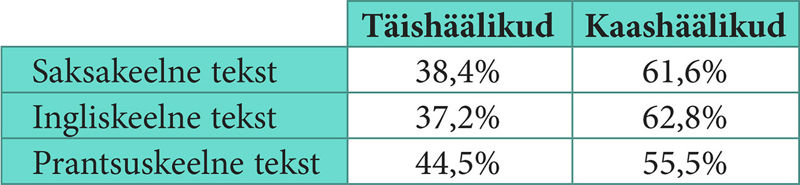
Ülesanne 156. Täis- ja kaashäälikute arv eestikeelses tekstis
Ülesanne 157. Eesti rahvuslik koosseis
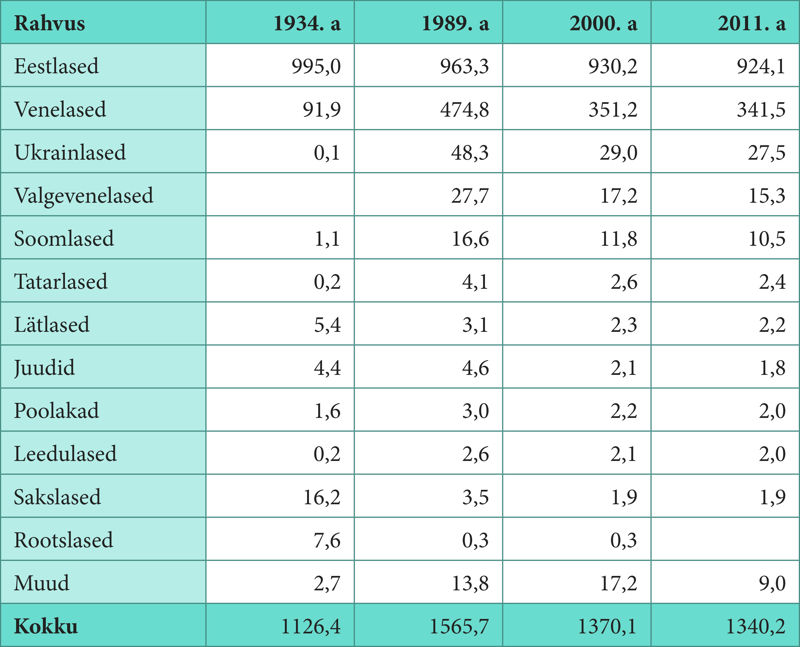
1934. a
- %
- %
- %
- %
- %
1989. a
- %
- %
- %
- %
- %
2000. a
- %
- %
- %
- %
- %
2011. a
- %
- %
- %
- %
- %
- Service provided by Star Cloud LLC