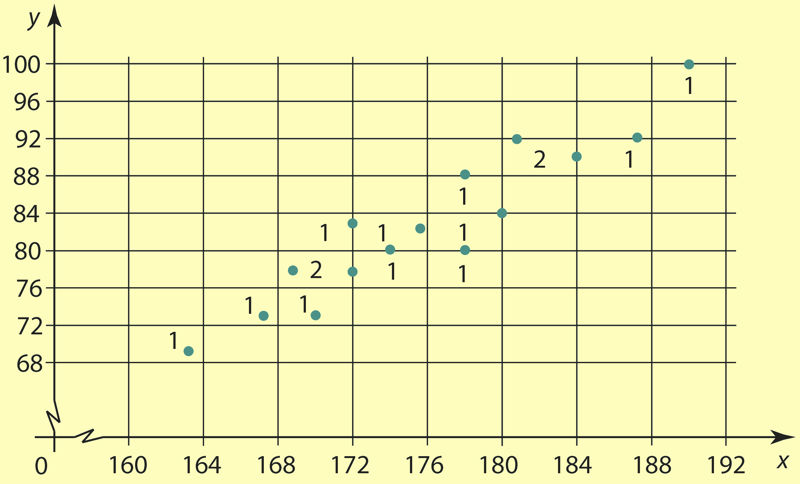
Vaatleme eelmise peatüki näitele vastavat korrelatsioonivälja, mis on esitatud joonisel 1.23. Paneme sellele väljale (joon.1.26) võrgustiku (ruudustiku). Sisuliselt jaotame tunnuste X ja Y väärtused klassideks. Loeme, mitu punkti satub igasse ristkülikusse, arvestades, et vahemikeks jaotamise korral loetakse kahe vahemiku piiril olev väärtus madalamasse vahemikku kuuluvaks. Loendamise tulemusi märgivad joonisel 1.26 tabeli lahtrites olevad arvud. Kandes need koos tunnuste väärtuste vahemikega või vahemike esindajatega (kui andmetega jätkatakse arvutusi) tabelisse, saame nn korrelatsioonitabeli.
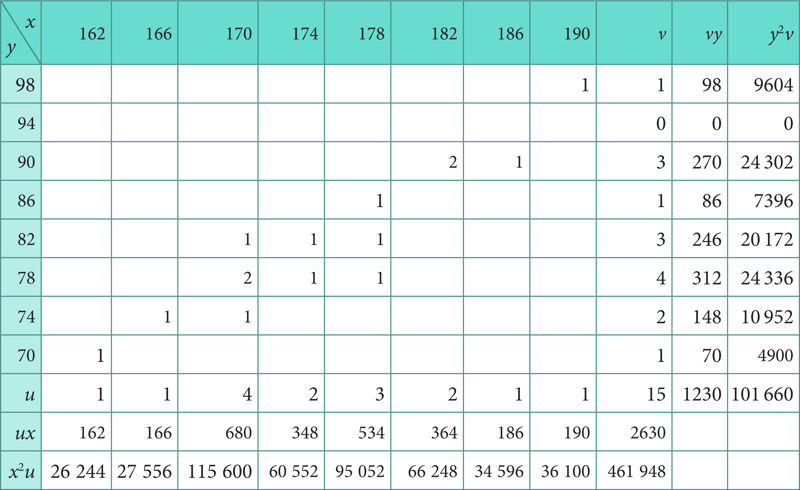
Korrelatsioonitabel koostatakse tavaliselt korrelatsioonivälja kasutamata. Selleks jaotame X ja Y muutumispiirkonna sobivalt vahemikeks (klassideks), kirjutame need või vahemike esindajad tabeli esimesse ritta ja esimesse veergu (või vastupidi) ning märgime tekkinud ruudustikku kriipsukesena iga konkreetse arvupaari. Hiljem loeme kriipsukesed igas kastis kokku ja kirjutame sinna saadud sageduse.
Edasiste arvutuste hõlbustamiseks on otstarbekas lisada korrelatsioonitabelile üks rida (u) ja üks veerg (v), kuhu kirjutatakse vastavalt veergudes ja ridades olevate sageduste summad. Nüüd moodustab esimene veerg koos veeruga v kogumi sagedustabeli tunnuse Y järgi ning esimene rida koos reaga u kogumi sagedustabeli tunnuse X järgi.
Kui korrelatsioonitabelis asendada arvupaaride esinemise sagedused suhteliste sagedustega, saadakse uuritava kogumi jaotus kahe tunnuse järgi.
Üldiselt esitatakse korrelatsioonitabeliga statistilisi andmeid siis, kui erinevaid arvupaare (xi ; yi) on väga palju ja tunnuste väärtusi on otstarbekas jaotada vahemikeks või kui täpselt ühesuguseid arvupaare on palju. Meie näite puhul pole tegemist kummagi juhuga ja piisaks eelmise artikli näites esitatud tabelist. Seetõttu tuleb siin esitatut vaadelda kui illustratsiooni keerulisemate juhtude jaoks.
Näide.
Leiame saadud korrelatsioonitabeli andmetel tunnuste X ja Y väärtuste aritmeetilise keskmise (
Kui arvutusi teha kirjalikult, on otstarbekas lisada korrelatsioonitabelile veel ridu ja veerge; meie näite korral on lisatud ux ja x2u väärtuste rida ning vy ja y2v väärtuste veerg, kuhu on kantud ka vastavad summad.
Nüüd:
σx2 =
σy2 =
Korrelatsiooniväli ja korrelatsioonitabel (näiteks joonisel 1.23 esitatud korrelatsiooniväli ja sellele vastav tabel peatüki 1.15 näites) esitavad tunnuste X ja Y väärtuste x ja y vahelist seost. See seos ei ole aga funktsionaalne seos, sest ühe muutuja igale võimalikule väärtusele ei vasta mitte üks, vaid sageli mitu teise muutuja väärtust. Ja mis veel oluline on: ühe muutuja fikseeritud väärtusele vastab teise suuruse üks või mitu erinevat juhusest sõltuvat väärtust. Nii näiteks vastab meie näite korral mehe pikkusele 163 cm vaid kehakaal 69 kg, kuid pikkusele 172 cm kehakaalud 78 kg ja 83 kg. Et kehakaalu väärtused just sellised on, on juhus. Kirjeldatud sõltuvust tunnuste X ja Y väärtuste x ja y vahel nimetatakse statistiliseks ehk stohhastiliseks sõltuvuseks. Lühemalt:
statistiliseks sõltuvuseks kahe juhusliku muutuja (suuruse) vahel nimetatakse vastavust, kus ühe muutuja igale võimalikule väärtusele vastab teise muutuja võimalik jaotus.
Ülesanded B
Ülesanne 191. Korrelatsioonitabel tunnustega pikkus ja kaal
Ülesanne 192. Matemaatika ja füüsika kontrolltööde hinded
- Service provided by Star Cloud LLC